From RAGs to Data Riches: How Squid AI Implements Retrieval Augmented Generation for Any Data Source


Generative AI is revolutionizing every aspect of business by providing previously unmatched cognitive processing power in a format accessible to all. When building a generative AI solution, more often than not, you need to be able to generate responses based off of information on which the model was not trained. A common design pattern for such generative AI applications is augmenting a Large Language Model (LLM) using an external knowledge source to enable data-driven responses to prompts or to create AI workflows based on your unique data. The data provided to the LLM, referred to as “context”, can take various forms, such as:
- Documents and text files
- Web page contents
- Images
- Tabular data
- Databases
- APIs
This data context is usually scattered throughout disparate sources, both internal and external. A company’s knowledge base might be found in a manual stored as a PDF, their customer correspondence might be stored in a CRM, and a corpus of their internal records might be available only through an internal API. While RAG applications can provide incredible value to a company, the disjointed nature of data sources poses a challenge: how do you get the right data to the LLM to deliver the right response in real-time? LLMs limit the amount of context you can send with a request, and the more context you include, the more expensive the request, so choosing the right information to send is incredibly important. At Squid Cloud, we took on this challenge and developed RAG solutions that, like everything in Squid, are designed to be flexible, real-time, and un-constrained to meet your product’s unique needs.
For example, Squid enables you to ask questions and get accurate responses or kick off a decision automation flow, such as: “Summarize the latest changes in analyst reports”, “List all devices that require a software update, and call a function”, “Automate sending all incoming documents with a healthcare-related topic to a healthcare function for nurse review”, and “Does my car policy allow renting a car?”
Squid provides three different RAG architectures depending on the use case:
- An architecture designed to use files, documents, and web pages as context, which is optimized for the unstructured data found in these documents. This solution most closely resembles the common RAG architecture.
- A solution that allows the user to provide external data using a function. The model determines when to trigger the function based on instructions, and then the function can access any external data source or even another AI model.
- A unique Universal RAG AI that utilizes data from any database you provide as context. You can interface with this solution in the Squid Console or from a client using Squid AI’s Query with AI functionality.
To distinguish Squid AI’s unmatched Query with AI functionality from other RAG architecture, we’ll refer to the more common version of RAG as “traditional RAG”.
Vector embedding
To understand the building blocks of RAG architecture, you need to be familiar with the concept of vector embedding. LLMs “think” in numbers. Every action a model takes is driven by a long series of equations that take in a sequence of numbers and return a new set of numbers representing the response to the user’s query. Speaking at a high level, to the LLM, every word is represented by a matrix of numbers. The numbers can be thought of as a vector in multi-dimensional space, but we can simplify this to make it more visually clear by reducing them to 2D vectors:
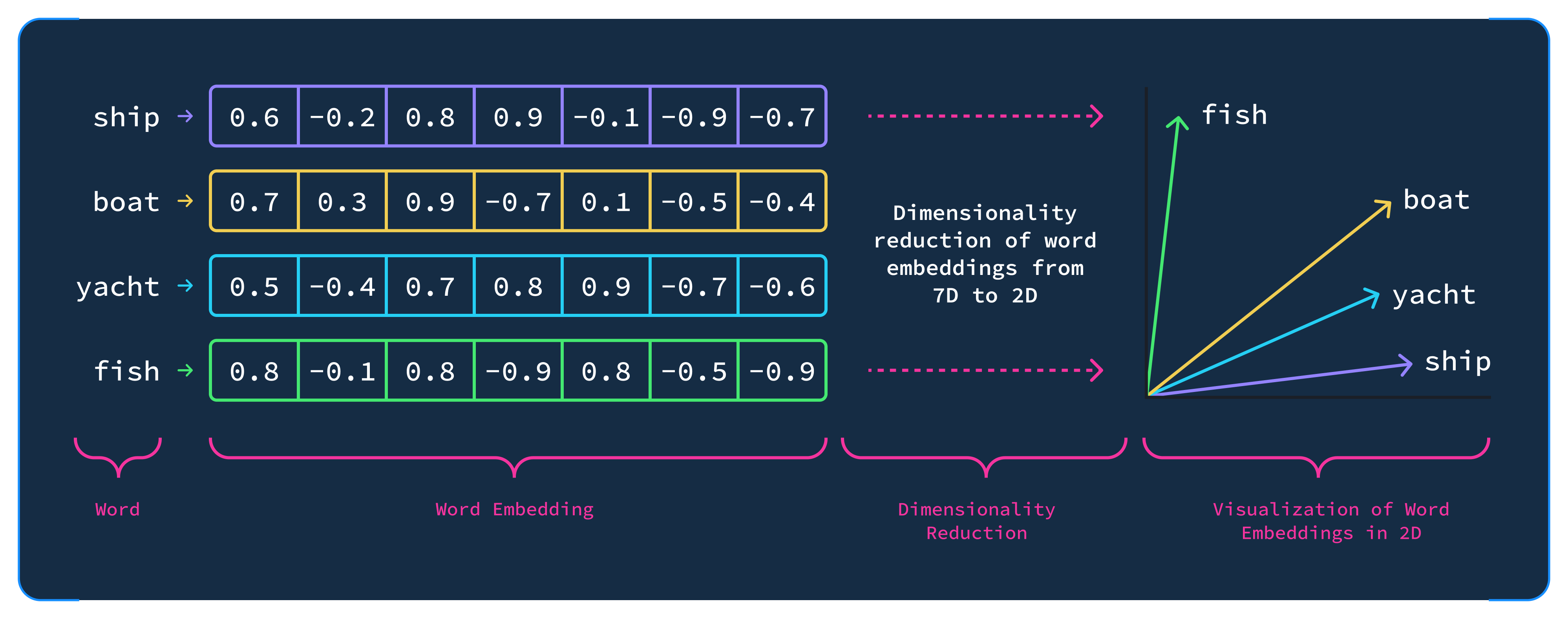
Words that are more similar in topic or concept will group together, just as we tend to categorize words by concept in our own minds. The process of embedding can therefore be thought of as turning words or phrases into matrices that represent how similar or dissimilar these ideas are to other ideas that the model has been exposed to.
Traditional RAG architecture
In a traditional RAG architecture, the context must be divided into chunks, and then embedded into vectors to categorize the contents. For example, a company policy document might include topics such as: vacation policies, equal opportunity policy, company values, onboarding steps, technology policies, and so on. Documents are divided into specific sized chunks—say, 2000 characters—that are then embedded to categorize their content. Other types of context could include a web page listing customer policies, a PDF catalog of available products, and a FAQ created to respond to common customer or employee questions. All of these resources are divided into chunks, and then these sections are passed to an embedding model to create vector embeddings.
Squid’s traditional RAG architecture is distinctive because of the pre-processing steps that enhance the quality of the context vector embeddings. For example, to improve quality and reduce costs, Squid AI RAG filters out low quality data like ads and HTML headers from website contexts. Squid also embeds and stores overlapping data chunks for data of high relevancy to improve the quality of LLM responses. Overlapping data chunks promote better responses since certain chunks will likely provide for better context than others. For instance, an important sentence might be cut off when a chunk is divided, but because chunks overlap, that sentence will be intact in the next chunk. Squid also removes these overlaps once we send the data do the AI so we don’t send duplicate data. The vector embeddings are then stored in a vector database.
When a client sends a query to Squid AI, the following steps take place:
- The query is embedded using the same embedding model used on the context.
- The query’s vector embeddings are then compared to the context embeddings to find the most relevant context for the request based on vector similarity. If there are any instructions provided to Squid AI, then these are also embedded and used to query the vector database for the appropriate context. Furthermore, Squid has the capability to store conversation history, and that history gets embedded to provide more context to the query.
- Using this embedded query and related context, the LLM then generates a response. For example, “How do I request a computer upgrade?” will have a certain vector embedding value that is similar to the part of a company document that discusses technology policies. The technology policies will be passed as the context, and the LLM will respond accordingly based on the context.
Squid’s Universal RAG technology works on any database, anywhere
The challenge of the traditional RAG architecture is that it has a low success rate when faced with structured data sources. This is a significant drawback considering that much of a company’s data is stored in a database or perhaps multiple databases. To address this, Squid went beyond the concepts of the traditional RAG architecture to implement a brand new type of RAG support that works on any database. We call this functionality Query with AI. Using Query with AI, you can ask questions about your data on the fly and get back human-readable responses without needing to write database queries.
Squid’s Query with AI feature uses knowledge of your database’s schema to help Squid AI determine what database query to run in response to a client request. To enhance this capability, you can provide descriptions of collections and fields in the Squid Console. Adding descriptions dramatically improves the accuracy of queries by improving the context provided to the model.

A client request to Query with AI can retrieve specific data or take an action based on data. For example, responding to “how many headphones were sold in March 2024?” involves querying a certain field in a database and then performing arithmetic. A request like “Create a line graph of headphone sales for 2023 and 2024” involves querying a certain field in the database and then using a plotting tool like python’s matplotlib to create a chart. Squid AI can also make predictions based on your data, like “Forecast next month’s headphone sales based on the item’s sale trends from 2023 and 2024”. Query with AI can handle all of these cases seamlessly, and many more, using your own data sources without the need to implement additional functionality.
When a client makes a request to Query with AI, the following steps take place:
- Squid gets the given database’s schema and descriptions, if provided. Squid then prompts the AI to filter that list by relevant tables based on the user’s prompt.
- Squid asks the AI to generate a query for the specified database giving the context of the user prompt, the selected relevant tables, and the table fields and descriptions (if any).
- Squid executes the database query and get the results as a JSON object.
- Depending on the client’s initial request, the result of this query might be passed to the client-facing model or additional action might be taken. For example, the query result might be passed to a function that generates a graph of the data.
- The final query result is passed to the client-facing model to send to the client. In addition to the query result, Query with AI shares the SQL or NoSQL query it made and the steps that were taken to get the query result, allowing insight into the process. This feature allows you to improve schema descriptions by understanding how the model came to a given result.
Developing your RAG applications with Squid AI
With this information, we’ve pulled back the curtain a bit to show what goes on when you use Squid AI in a RAG application, but Squid AI actually abstracts these complexities of the RAG pipeline in our fully-managed platform. When using Squid AI, you don’t have to worry about the RAG architecture or about building indexing and retrieval pipelines. Simply integrate your data sources with Squid and immediately unlock the power of RAG.
Here are some ways that companies are using Squid AI right now:
Providing knowledge-based responses
Using data sources like documents and web pages, companies can create custom AI chatbots to provide contextual responses to queries. These chatbots can be used by employees or customers to find topical answers faster than ever before. For example, you can find out company policies within a large body of information in a matter of moments, including the context that was used to provide the answer. Squid AI’s approach to generating responses using unstructured data abstracts the complexities of indexing; you provide the data sources in the form of raw text, file uploads, and URLs, and Squid manages vector embeddings to ensure accurate responses in real-time. To learn how to create a chatbot to answer questions using context, try out a Squid AI tutorial.
Producing data-driven insights
One of the most exciting applications of the RAG design pattern is its ability to generate relevant responses based on your data. This technology allows you to generate charts on the fly for presentations and dashboards, find out real-time key metrics, and query data for any purpose without the need to write complex queries.
With Squid’s Query with AI functionality, you can integrate with any data source, auto-discover your data’s schema whether it’s NoSQL or SQL, and then generate context from your database schema to run queries on your data in real-time. While many individual database products are actively working on or currently offering some version of this functionality, Squid AI works on all of your data sources, including on-premises, allowing for an incredibly powerful plug-and-play system that fits the needs of even the most complex applications.
Implementing AI agents
An AI agent is a decision-maker which lets you respond to distinct user queries by kicking off different sequences of actions based on how the agent categorizes the query. For example, if a user says they wish to return an item, the agent will categorize this as an order-related query and kick off a sequence that pulls data about the user’s order. Alternatively, if they ask what store hours are, this kicks off a separate sequence that queries the hours for a store at a given location. The AI agent design pattern can be achieved using the instructions you provide to your Squid AI assistant, through AI functions that run code in response to user queries based on the instructions you provide, or a combination of both methods.
Securing your RAG solution
Since RAG applications provide responses based on your data, it’s incredibly important to ensure that only the right users can access your solution. Squid secures your AI solutions using security functions in the Squid backend written in TypeScript. To learn more about securing Squid AI, check out the documentation or try a tutorial where you build and secure an AI chatbot.
Build your AI solution today
Squid’s RAG capabilities go beyond anything else available on the market today by enabling you to perform requests on any data source anywhere, including MongoDB, Oracle, Snowflake, Microsoft SQL Server, MySQL, CockroachDB, PosgreSQL, DynamoDB, Clickhouse, BigQuery, and much more. Squid has connectors to any database or data warehouse out of the box. To learn about the capabilities of Squid AI and see how to get started, you can view the documentation, try a tutorial, or check out a code sample. To discuss your use case and build a Squid AI solution with us, reach out via email or on our Discord server.